Pay Attention: A Beginner’s Guide to Transformer Architecture
Introduction
Generative AI has been an overwhelming source of interest in recent news. This post aims to move slightly beyond the popular articles on Large Language Models (LLMs) and to explain their particular architecture to data scientists and engineers that are yet to look under the hood of LLMs. This post will, however, remain somewhat brief, and won’t provide insight into variations on this architecture or the many ways in which it can be applied. The aim is to provide a basic understanding of the architecture and the way in which it differs from previous generations of language models.
Generative AI is a subset of traditional machine learning and the models that underpin generative AI have learned these abilities by determining statistical patterns in huge datasets of content that were originally generated by humans. These Large Language Models (LLMs) have been trained over long periods of time on trillions of words, utilising large amounts of computational power. The result is a foundational (or base) model, often with billions of parameters, exhibiting emergent properties beyond simply language. Much of the current research in LLMs is focused on unlocking their ability to break down complicated tasks, apply reason, and solve problems. Some foundation models mentioned in recent news articles will likely sound familiar:
- GPT
- Bloom
- BERT
- LLaMa
Underlying the architecture of some of these models, notably GPT, is the Transformer. This framework was first introduced by Google researchers in 2017, in a paper titled Attention Is All You Need. The paper proposes a new type of neural network architecture capable of replacing the traditional Recurrent Neural Networks typically used in language models. However, in order to understand the Transformer, it makes sense to first understand the way in which previous generations of language models worked.
Recurrent Neural Networks (RNNs)
RNNs are a type of artificial neural network designed to recognise patterns in sequences of data, like text or speech. They achieve this by storing a “hidden state” from step to step, allowing them to capture information from the past to use in the future.
While RNNs present a powerful generative algorithm, they are limited by the amount of memory and compute power required to perform well at generative tasks. As an example, let’s imagine a next-word prediction problem. Consider the following sentence:
"Sally, who moved to Spain in 2005 and loves the culture, the food, and the people, still struggles with the _______."
The blank term could be filled with the word “language” to make the sentence meaningful. However, the particularly helpful information (“Sally” and “Spain”) is quite far from the blank term, separated by a long sequence of words. RNNs, due to their sequential nature, can have difficulty maintaining linguistic context over long sequences due to the vanishing gradient problem, whereby the influence of the input information decreases over time and with distance in the sequence. As an example, using an RNN with Keras1 , the suggested term was ‘bureaucracy’, an intriguing guess but not one that would immediately leap out to someone keeping in mind the entire text.
Since RNNs process sequences one element at a time, processing a sequence of length n requires the RNN to perform n steps of computation. The name recurrent, in fact, refers to the repeated performance of a task for every element in a sequence. The sequential nature of calculation in an RNN makes it difficult to parallelize; a common technique for speeding up computations, moreover, RNNs maintain a hidden state which is passed from each step in the sequence to the next. This state needs to be stored and updated at each step, greatly increasing memory usage over longer sequences. As you can see, as an implementation of an RNN is scaled in order to see more words in the text, the resources required by the model are significantly scaled - the computational and memory requirements grow exponentially as the window of text seen by the model is increased.
As you can see, to successfully predict the next word, models need to see more than just the previous few words or they reach results like ‘bureaucracy’. It’s important for models to gain an understanding of the whole sentence or even the entire text. The problem here is that language is extremely complex. For example, homonyms provide great difficulty to the RNN method. Let’s consider the following:
"She is looking for a match."
This could mean she is looking for a match to light a candle, or it could mean she is looking for a partner or she is looking for a strong opponent in a game. In this case, it’s only within the context of more of the input text that we can see what kind of match is meant:
“She had always been competitive in tennis, enjoying the thrill of a good game. After years of training and honing her skills, she found herself at the district championships. She isn’t here to entertain. She is looking for a match.”
Self-Attention
Unlike RNNs, Transformers are capable of considering all words in a given sentence simultaneously and weight their respective importance accordingly. They do this via a mechanism called self-attention (often just ‘attention’), allowing the Transformer model to capture long-term dependencies and parallelize computation in an effective way. This method greatly outperforms both recurrent neural networks and convolutional neural networks at generative tasks. To better understand how attention in a transformer model works, imagine you are reading a book and you come across this sentence:
"Despite the heavy fog last night, the dog managed to find its way back home."
If someone asks you who found their way back home, you would likely focus on or “attend to” the word “dog” because it’s the most relevant word in relation to the question being asked. In a similar way, the attention mechanisms allows the model to weigh or “attend to” different parts of the input when generating an output (also known as a completion). In this way, the model might give higher attention to the words “dog” and “home” when asked the question “who found their way back home?”. Also, note that the weights in the attention mechanism are learned during training, which means that the model learns what to pay attention to based on the data it has been trained on. This ability to focus on different parts of the input based on their relevance makes transformers powerful, especially when dealing with long sequences of input data like sentences or paragraphs, as it helps them capture long-distance relationships between words or features. Referring back to an earlier example, we can create a sequential graph of the processes underlying an RNN:

In contrast, we can now see that the transformer uses self-attention to understand the relationship in a different way. Rather than moving sequentially, each input word is analysed (and will therefore be weighted) in relation to every other word in the input:
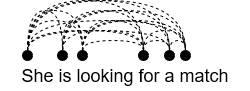
The power of the transformer architecture lies in its ability to learn the relevance and context of all of the words in a given sentence. It can apply attention weights to these relationships so that the model learns the importance of each word to each other word no matter where they are located in the input, significantly improving the model’s ability to encode language.
Transformer Architecture
Now, with our understanding of self-attention, we can begin to examine the architecture of the Transformer more closely. We can produce a simplified version of the original diagram from the Google paper and step-through how each layer works:
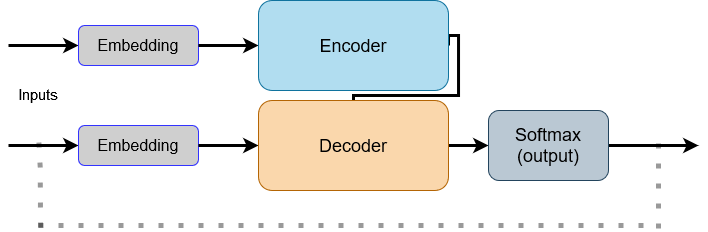
As you can see, the transformer is primarily formed of two distinct parts, the encoder and the decoder. The inputs to the model are to the left, while the outputs are to the right-hand side.
The Layers
Inputs: The input to our Transformer is text in the form of a prompt. A prompt is any form of natural-language query a user might wish to get a response for. Of course, given that machine learning models are essentially giant statistical calculators, we need some way to represent natural language numerically. Therefore, before text is processed by the model, it is tokenized, a procedure in which the text is represented by numbers, with each number indicating a position of the word in a dictionary of all the possible words the model can operate with. Note that tokenization doesn’t necessarily have to break down the text into individual words. Sometimes, a token can represent just a single character, a word, or even a subword or syllable, depending on the tokenizer used. The important thing is that the same tokenizer used at input is the same one used at the output.
Embedding: With the text transformed into a numerical representation, it can be passed to the embedding layer - a trainable vector embedding space. Here, each token is represented as a vector and occupies a unique location in this high-dimensional space. To make sense of this layer, and for simplicity, we can imagine it as simply a three-dimensional space (though it’s typically in the region of hundreds!) in which tokens are represented by a vector size of just three. We could then plot some of these tokens:
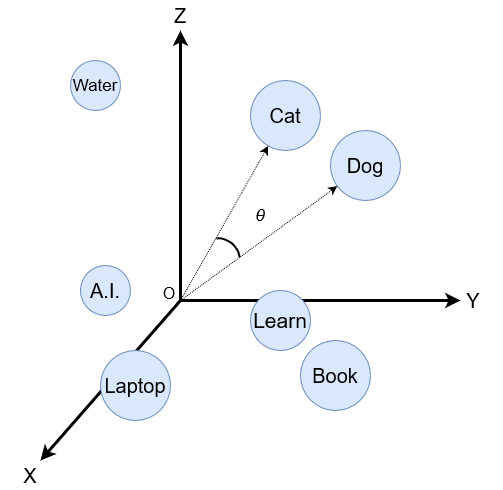
It’s easy to then calculate the distance between the words using the angle between them, the image includes ‘Cat’ and ‘Dog’ as examples. In this way, we can determine the relationship between the words, we can see if they are close to each other in the embedding space or if they are more distant and less associative. A positional encoding is also added in this layer to give the model information about the relative positions of the tokens in the input, as the Transformer does not inherently understand the order of the tokens in a sequence in the way an RNN does. In short, vectors representing each token capture semantic information related to the tokens, words that are semantically similar will therefore have similar vector representations.
Encoder and Decoder: The vectors, now carrying information about the input tokens and their positions, are then passed to the encoder and decoder, specifically, to their respective self-attention layers. In this layer, as discussed earlier, the model ‘attends’ to the relationships among all the tokens, assigning different weights to signify their importance in relation to each other. This isn’t simply done once. The Transformer incorporates multiple self-attention heads that operate independently, each learning distinct aspects of language, such as relationships between entities or activities within a sentence. The specific focus of each head is not pre-defined; they each learn autonomously with enough training data and time, each potentially uncovering different linguistic elements. The number of heads varies from model-to-model but it’s common to see up to 100 in a single Transformer.
After the attention process, the weighted inputs are then processed through a fully-connected feed-forward neural network, outputting a vector of logits. These logits are essentially raw predictions that represent the likelihood of each token in the vocabulary being the next word.
Softmax Output: Finally, a softmax function is applied to the logits, normalizing them into a probability distribution over the models entire vocabulary. The token with the highest probability score is deemed the most likely next word. There are, however, various methods which can be used to make the final selection, allowing for a more nuanced prediction beyond simply picking the highest probable token.
Now that we have seen the end-to-end architecture of the Transformer, let’s conclude this post by using one, let’s use GPT-3 to summarise the above:
import openai
import os
openai.api_key = os.getenv('OPEN_AI_API_KEY')
# Read in my blog post from a text file
with open('prompt.txt', 'r') as file:
article_text = file.read()
# Add in my instruction to the end of the prompt
prompt_text = article_text + "\n\nI've written this article, can you write a final conclusion or summary for it?"
# Use GPT-3 to generate the conclusion
response = openai.Completion.create(
engine="text-davinci-002",
prompt=prompt_text,
temperature=0.5, # This determines the randomness (or 'creativity') used in the model's responses
max_tokens=200 # This specifies the maximum length of the output
)
print(response.choices[0].text.strip())
And we get the following conclusion from GPT-3:
Conclusion
This article has endeavored to provide a comprehensive look at the Transformer architecture, the powerful mechanism behind some of today’s most advanced Large Language Models (LLMs), such as GPT. While traditional models like Recurrent Neural Networks (RNNs) have their merits, their ability to handle long sequences and maintain linguistic context over time is limited. The transformer model effectively addresses these limitations through its unique structure and the use of the self-attention mechanism.
Transformers ingest sequences as a whole and assign weights to the tokens based on their relevance and context, regardless of their positions. This self-attention mechanism enables the model to capture intricate dependencies and relationships between words, thereby improving its language encoding capabilities.
In a nutshell, the Transformer model takes in tokenized inputs, embeds them into a high-dimensional space, and applies positional encoding to maintain word order. Then, through the encoder and decoder layers, these vectors undergo self-attention, where they are weighted based on their contextual relevance. The multi-headed nature of this process allows different aspects of language to be learned concurrently and independently. The output is a vector of logits, transformed into a probability distribution for each token in the vocabulary. The most likely next word is then selected, with methods available to introduce variability in this choice.
Understanding the fundamentals of Transformer architecture and the mechanisms behind it can be a vital step for those interested in delving deeper into the field of AI and machine learning, particularly in the area of language models. Its innovative approach has been revolutionary in dealing with sequence data and language processing, and it continues to be the backbone of many cutting-edge models today.
-
Keras is a popular deep learning framefork. For those unfamiliar: https://keras.io/. ↩